Step One: Downloading, Installing, and Registering the trialIn many cases, especially with smaller companies, registering a trial can be a trial in and of itself. Though one does have to give contact information for the registration which I usually dislike, even as I understand, a key from the e-mail entered into the database administrator as you open the application is all you need to register, so it is straightforward. There is also something else that I see as great foresight- there is a way that you can reset your activation, I'm assuming if you need longer to evaluate. That this is already present speaks volumes about their understanding of the desired audience. The installation itself is pretty standard, so nothing to report there, which is a good thing when it comes to installers.
Rating for Installation 9/10Notes: One point deducted for having to give particulars to get an evaluation key)
Step Two: Deciding on a projectI'd already been working on a project for a game launcher/cataloger from a
request in a thread. I hadn't decided on the data store for the application, so this thread on VistaDB came at a perfect time.
Step Three: Database DesignThe application will have a main
Games table, with most of the primary information requested.
Two foreign keys are going to be on that table, both linking to
GameCompanies to detail the Publisher and Developer.
GameCompanyContacts will be connected to that table, to allow many contacts for each GameCompany.
GameCustomFields will be connected to the Games table, to allow the user to enter custom fields to be displayed on the particular game.
GameLinks will also be connected to the Games table to have URLs for resources connected to the game (for support pages, mobygame page, etc)
GameTags and
GameGenres will be connected to the Games table by two pivot tables (
Games2Tags and
Games2Genres) to allow many GameTags and GameGenres to be re-used amongst games.
Creating these tables was a lot easier than with other solutions that I have utilized, because of the inclusion of an administration tool.
 |
| Vista DataDB Builder |
The VistaDB Data Builder is a full fledged tool, useful in its own right. It allows the administration of all objects in the database, direct SQL, and manipulation of the objects in LINQ.
I haven't been able to work with the LINQ objects, and have a forum post on that particular subject in the works, so I will update with how that is going. But the graphical database administration works wonders.
The first step is to create the database and tell the administrator where you want to store it.
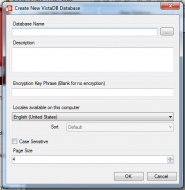 Review of VistaDB
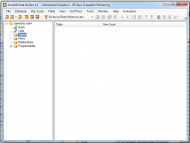
Review of VistaDBAfter this, the main window appears with an appearance very similar to the SQL Server Management Studio.
 Review of VistaDB
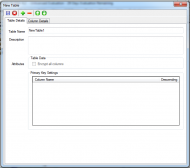
Review of VistaDBClicking the new table button brings up a window to create the table, and after the table is created, columns can be added.
 Review of VistaDB Review of VistaDB | 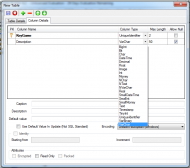 Review of VistaDB Review of VistaDB |
It's worth noting that the buttons in the toolbar are not all related to the tab that you're on; the save and cancel buttons are for the entire table, but the other buttons relate only to the columns tab.
As columns are created, each is typed with a standard SQL type, and clicking in the first column of the table sets that tablecolumn to be part of the primary key. A point I noticed at this juncture is that modifying multi-column keys seems to run into some problems at points. It's not all the time (indeed, I had problems reproducing it to the point that I couldn't narrow down the steps), and is easily resolved by deleting the columns in the key and re-adding them, but it is something that I noted.
After columns are added to the key, whether they are sorted ascending or descending can be set in the first tab as the fields in the key are shown here.
So, after adding all of the tables, I then decided to create foreign keys. For the most part this was pretty straightforward; go to the table where the foreign key is to be created, select the foreign key section, and click the add foreign key button.
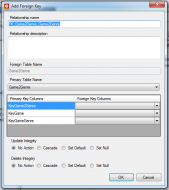 Review of VistaDB
Review of VistaDBIn the dialog, the keys of the parent table for the FK are shown, and the other side of the key must be assigned. The keys also support cascading updates and deletes. This works well in most cases, but as shown above, for this application, there are many to many relationships to be represented by pivot tables. In my case, the pivot table was defined as shown in the image above. For each FK, you have to assign all fields, which doesn't work for this.
But this gives the perfect segue into the query analyzer.
Clicking the query leaf of the tree view opens a view very much like the SSMS query analyzer. Type in the SQL and go. Since the particular setup that I wanted wasn't covered by the interface, I didn't know if it would work. But I tried the SQL, and indeed it did create the relationship I wanted, as shown below.
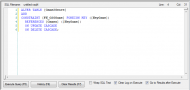 Review of VistaDB Review of VistaDB |  Review of VistaDB Review of VistaDB |
At this point, the entirety of the database is created, and I've had to touch SQL very little. The SQL that I did touch worked without a hitch, so I have little doubt that I could have done the whole operation in SQL if preferred. And this touches only the surface of the capabilities of the Data Builder- it's a full fledged application in and of itself.
Rating for Data Creation 10/10So the first three steps of the application are done (for now), and VistaDB has proved itself quite capable thus far. Next up... adding the data sources and manipulating data from within the application.
Step Four: Database Management/UseI've found that as I've delved deeper into VistaDB, it's definitely giving you a lot for your money if you're already invested in SQL Server as a RDBMS platform. Unfortunately, that has made the few hiccups I've had stand out.
My first decision was how I was going to handle database objects. I'm going with the MVVM (Model-View-ViewModel) pattern to get some more practice in for work with that pattern. At first, I was also going to use entity modeling, as that is sort of what I'm doing at work also - in that case using EditableObjects to represent the data objects. But I couldn't get the entity modeling going as I stated above, and still have not heard back on that particular thread. Instead, I decided to use typed datasets, which is also something I haven't used before. Looking back, it might have been better to only use one variable, instead of the several that I've used, but I'm committed now.
The first problem I had was in generating the table adapters for views in the database. For some reason, the table adapter was created, but it was not exposed in the dataset, so I had to hack it. I've not received a response on that either, so I'm not sure if that's something with the implementation of views, or Visual Studio- I'm leaning towards the latter. I also have found a problem with recursive queries, i.e. I wanted to use a function to return the result of a query on a pivot table as a comma delimited list.
DECLARE @r VARCHAR(200)
SELECT @r = ISNULL(@r+',', '')
+ gt.description
FROM GameTags gt JOIN Game2Tag g2g ON
gt.keygametag = g2g.keygametag
WHERE g2g.keygame = 1
SELECT @r
This only returned the results from the last row. No matter how I simplified it (I removed the joins and everything else to make it as simple as possible, and still no go).
On another note, if anyone has any other ways of doing this that don't involve cursors, I'd appreciate the help.I also had a problem in that I couldn't return multiple results from a query in the query analyzer. But I could return multiple tables in a stored procedure, so that turned out not to be a problem- just an inconvenience.
The documentation is very straightforward in informing the user that all T-SQL is not supported, and giving a pretty extensive list of commands that aren't supported, though this was not listed. I suppose it's jarring, because other than these few cases, it feels like I am using SQL Server, which is amazing.
Also of note, of the three problems I've had, I've posted questions on the community forums, and have yet to receive a response. As none of them have been anything but annoying, I've not resorted to pre-sales support, so I don't blame this on their support- I'm just saddened that there doesn't seem to be as much chatter on the forums as I like for software of this type. At the end of my project before making my final decision, I'll go through support on one of my issues (or sooner if I come across a show-stopper), to evaluate their support.
Also of note is the fact that I've had to touch SQL very little in managing the database, and again, when I have, it's been straightforward, so it's been quite nice so far to have both options.
I'll update this section if there's anything of note as I modify and manage the database.
Update (2011-05-28): I've
received a response regarding the recursive query, and they are not supported. The staff member that responded
pointed me to a thread that gave a pretty involved explanation as to why. It's disappointing, but as I said, they're pretty up front about only supporting a (very large) subset of T-SQL. I am encouraged at the speed of the reply, though; I'm not sure why the other threads languished, but this one was a pretty fast turnaround.
Addition (2011-06-04): Experimenting with the database at the same time as I was developing was causing a bit of problems, as would be expected. I have begun to keep backups of the database, but I also had some test data that I was using, and putting it in twice was too many times, and I wasn't really wanting to write sql scripts to load the database. I found the solution under the File-> XML Import and Export.
Once you select the menu option, a quite simple screen appears that is has a power that belies this.
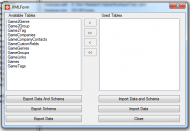 Review of VistaDB
Review of VistaDBYou can export the data, the schema, or both to simple xml documents. When exporting, it seems obvious that you have to select tables. When importing the schema and tables, the tables list is empty, so just pressing import seems the right thing to do.
When importing data by itself, you have to select the tables that you want to import.But this has saved me a
lot of time and frustration.
Update (2011-06-06): Though it should be obvious, since autoincremented key support is at the table level (d'oh!) if you export the data without the schema and then import it into a database with non matching seeds for these keys, you need to update them. The data will import correctly, but then when you try to insert, you will get errors as it's attempting to insert a duplicate key.
Rating for DataBase Management/Usage 9/10 Notes: Increased from 8/10 to 9/10 after working a bit more with the db on 2011-06-04
Step Four: ProgrammabilitySo, now I'm to actually doing something with the database.
Stored ProceduresBecause of how some things link together, and the requirement that in querying for this data, I need the results of a previous query, I decided to use stored procedures for this.
Standard DDL works when using stored procedures, and I found that the graphical interface was also pretty straightforward, and had the added benefit of restricting your data types to supported datatypes.
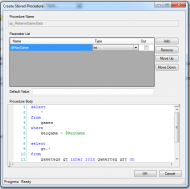 Review of VistaDBFunctions
Review of VistaDBFunctionsPretty much the same as stored procedures, with the added benefit of supporting a construct that I thought wouldn't be available - table value parameters. I don't know why they aren't available in stored procedures (and indeed, I'm not sure that they're not, they just aren't touted in the documentation as they are for functions, nor are they available in the interface, so I'm not inclined to believe offhand that they are).
The interface to create them is nearly the same as the stored procedure interface, except for when a table return type is selected; in that case, it allows you to define the table.
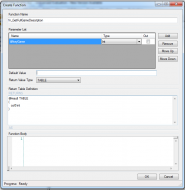 Review of VistaDB
Review of VistaDBThis brought me to a rather bad part about it, and one that I'm still attempting to find if there is a way to fix. Fortunately, I'm using two different databases, and backing up often, or this would have been rather off-putting.
In the interface, it doesn't allow you to define a table as an input type, so I created the DDL to allow it. Something rather pedestrian, i.e.
CREATE FUNCTION [fnGetPublishers] (@games TABLE)
RETURNS TABLE ( Description VARCHAR(50) )
AS
BEGIN
return select gc.description from gamecompanies gc where gc.keygamecompany in (select keygame from @games);
END
Then to call it
DECLARE @GamesTemp TABLE (
KeyGame int
);
INSERT INTO @GamesTemp (KeyGame)
SELECT KeyGame
FROM Games
WHERE KeyDeveloper = 1;
select * from fnGetPublishers(@GamesTemp);
Apparently I did something wrong in my DDL, because from then on, the function leaf of the treeview wouldn't open, and I'd get an error invalid syntax near SELECT everytime I opened the database or tried to open the function leaf- to the point that I had to force quit the application. The database still worked, and I was able to take my last edits and transfer them to my last copy of the database. But I'm not sure if this is a shortfall of the Data Builder or the database not to be able to handle the code.
CLR FunctionsIn my last section, I lamented the lack of recursive queries. I now lament no more, for it forced me to look into CLR functions. CLR functions are basically the use of managed code assemblies to be able to be called from your database. And they allowed me to do what I was going to do with recursive queries, and a lot more! They're available in SQL Server, but I used them only scarcely. But now, I'll be using them a lot, I think.
And they're quite easy to use:
1. Create your code project, using the attributes that they set forth to mark your methods as functions or procedures.
2. Load your database in to the Data Builder.
3. Use some SQL to load the assembly and define the functions (or use the nifty UI to do the same)
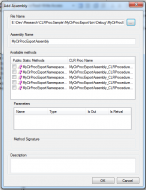 Review of VistaDB Review of VistaDB |
| The Nifty UI (TM) |
And you're done! The functions/procedures are called as any other procedure, and there's a way to use the same context that the function is being called from to connect to the database. So any support you want to have is just a step away. And the assemblies are loaded into the database, so there's nothing else to distribute.
Rating for Programmability 7/10 Note: Would have been higher, but that problem with incorrectly programmed functions that are correct in SQL worries me a bit.
Step Five: Integration and UseI decided to use strongly typed datasets with the VistaDB database. It should also be noted again that my experience is with Visual Studio 2010. And a caveat is that I've only touched on typed datasets before this, so a couple of these points might be due to that lack of experience, though I've searched and found no other incidences of the points that I did find.
The actual use of the database from an interface perspective isn't any different from using a SQL Server connection. I utilized the inbuilt Data Source Configuration Wizard, and was able to point it to my instance of the database and it built the tables and adapters with few problems.
First, the table adapters for the views were not exposed. I'm not sure if this is normal; it doesn't seem to be from my searches on the internet. But this was quickly solved, as I was able to manually put those properties in the designer code file. It is tedious, having to change this every time I change anything in the dataset, so I keep a pristine copy with all of the methods available, and merge those into the file every time it's regenerated. But still a bit of a pain.
Second, it doesn't seem to recognize composite keys on views. I have composite keys on a few of my relational tables that I use to create many-to-many relationships between a few of my objects, and I had to manually update the keys on the table to match the fact that the view could have many instances of the same key, as long as the composite key was satisfied. Again, not a major issue, just something that I have to do every time the dataset is regenerated.
From there, everything was gravy. I created a model to contain my data, and exposed methods to load the datatables and expose the correct dataviews/tables. The standard databound controls worked flawlessly against the data layer, and I was able to use the standard binding manager/binding contexts to access and update the data. I was also utilizing a stored procedure to update one relationship behind the scenes, and that worked flawlessly also.
Rating for Integration 10/10 Notes: The dataset stuff is annoying, but not insurpassable. If that is the normal behavior of the dataset generator, then I'd give it a 10/10- it's pretty transparent and just like using SQL server, which is pretty much the highest compliment I could give it. The fact that this section is so short speaks to how much I was working with the program rather than the database, which is what I want at this stage of the development.
Notes: Updated rating to 10. I tested against a SQL Server database using typed datasets, and it doesn't create the adapters for those views either.
Step Six: PerformanceOff to a test project to test performance. I had an input file for a client, so I decided to use that since it was laying around. It's a .CSV file, with 46 fields defined, so I set up a new database with those fields, and a separate key from the one in the file so I could scale it. The file only has 1894 records, and while that is a decent amount, I wanted to get up to 100000 records being inserted for a real test. I didn't use a typed dataset in this case, and made my own model, loading the data from the file into a list of objects that implemented the IEditableObject interface. Then I created a cache of records- at first I used the standard 1894, but then I used a random assortment of the objects. The results are below.
| Run | Rows | Total Time (mm:ss:ff) |
| 01 | 1894 | 00:00:06 |
| 02 | 1894 | 00:00:06 |
| 03 | 10000 | 00:36:12 |
| 04 | 10000 | 00:36:84 |
| 05 | 25000 | 01:38:05 |
| 06 | 25000 | 01:46:57 |
| 07 | 50000 | 03:43.88 |
| 08 | 100000 | 06:27:62 |
| 09 | 100000 | 09:16:12* |
| 10 | 100000 | 08:44:46* |
* - the last two tests were run on my work machine (Core 2 Duo E8500 @ 3GHz), which is quite a bit slower than my home machine (i5-2400 @ 3.3 GHz).
I should hope not to be processing more than 100000 rows at once on any application that I am using VistaDB for- indeed more than the base amount of the file would be an aberration. But I just wanted to see the relative processing power, and given the hardware, it does seem acceptably performant, even on those unrealistically large datasets. And on the client file, it was blazing. In comparison, that same file using Access takes about 30-45 seconds to process.
After loading the table a few times, I had 138,273 records. To get join performance, I wanted to have another table with a similar number of records. So from within the Data Builder, I created a copy of the table, then ran an insert into from the original table to copy the data. This operation took 29.593 seconds.
Then I ran a pretty simple join on the table, on a FTS indexed field, and on a non-indexed field. Creating the index on tables of that size took only a couple of seconds, then a like query on the FTS index for a total of 152 records took 2.658 seconds to run. A join on a non-indexed field with a where clause on a FTS indexed field for a total of 11,560 records took 3:21.9 minutes to run. Indexing that field took the query down to 2:12 minutes. These are pretty extreme cases; in standard use, I didn't have to wait for queries to return. But I wanted to get an idea of the capabilities of VistaDB.
Rating for Performance 10/10 Step Seven: SupportAs I stated above, I had a couple of issues, and utilized their support e-mail for a couple, and the forums for a couple more. They do seem to frequent the forums, though there is a bit of a turnaround time, and it does appear that it depends on where the help request is posted; I had a problem getting the entity framework to function, and I never received a response to that post- that post was in the Entity Framework section of the forum. In contrast, questions in the SQL Related and General forums were answered within a few hours.
And I was quite impressed with the e-mail support- I had a problem with the CLR procs, and though I found a way around it, they followed up on the e-mail, asked some pertinent questions and for examples to replicate the problem, and when they couldn't get it fixed immediately, followed up again to make sure that this was not a blocking issue so that they could prioritize it accordingly in their backlog.
I attempted to see how frequently fixes and patches are being posted (and new versions), but I couldn't find anything beyond the latest release, so no information on that front.
But by the speed and nature of the responses to the few queries that I did have, I have a pretty good feeling about the support.
Rating for Support 9/10 Summary and Final AnalysisTruthfully, when Renegade first brought up VistaDB and talked about how it compared to SQLLite, I was hoping that VistaDB would somehow fall short, even as I wanted something more than SQLLite or SQL Server Express (or Access). It is quite an investment. But for that investment, you get a stable, seemingly well established and supported product, with tools to make development easier.
It's pretty much a no-brainer that I'm going to go ahead and buy as soon as I get the money- which is the one con of the product, but understandable in comparison to what you get. The mISV program is a considerate gesture that does make it more affordable for small shops, and a program that I plan to take advantage of.
Final Rating 9/10 - a buy rating.
Other ReviewsC-Sharp CornerDotNet FreaksCodango

