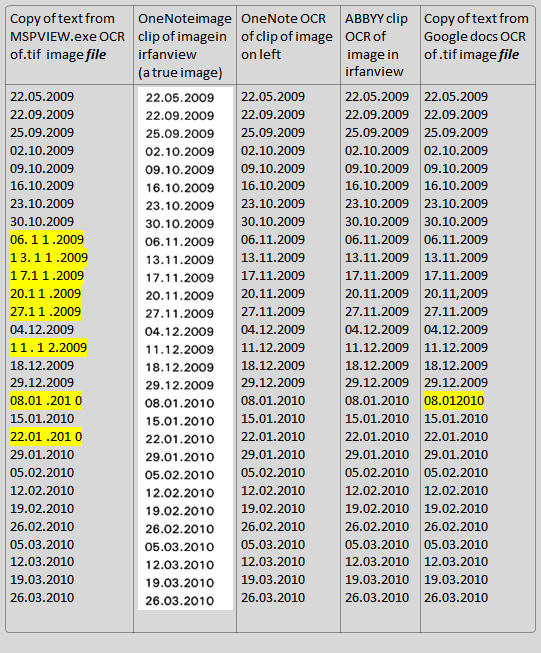
Objective:To run a quick comparison of the difference in accuracy between some of the different OCR capability available on/from my laptop and in the Cloud:
○ MS Office 2007 MSPVIEW.EXE (laptop).
○ MS OneNote (laptop).
○ ABBYY Screenshot Reader (laptop).
○ Google docs (Cloud).
Method:Input data is in the form of a .tif image document, made by scanning a laser-printed document (black on white). The image was of a date-ordered financial statement.
For the purposes of the comparison, I just focussed on a range of dates in the date column, not the whole document image.
The table below has had all the OCRed results put into the same font and font size, and the single image has been resized/aligned, so that it is easy to compare the results across columns.
Results: ○ The errors have been highlighted in yellow.
○ It is evidently a tie between
OneNote OCR and
ABBYY clip OCR, both with 100% accuracy.
○
Google docs OCR is a very close second, with only one error - it missed a dot(!).
○
MSPVIEW seems to have made no data errors, but has inserted spaces where there were none.