PDF Generator
Here is another example of a StandAlone module that could theoretically be part of the Turbo Processor.
Suppose you are doing web research.
For background, MilesAhead wrote me a "Beta" version of his BBSS that creates paired lists of titles and URLs.
Here is Mouser's Newsletter:
https://www.donation....msg343854#msg343854We have decided we want to look at the NANY section.

1. Open them all up in tabs in Firefox. (Note - there seems to be a bug and this doesn't work right in Pale Moon.)
2. MilesAhead's BBSS reads the tabs and creates a paired list of your research tabs as titles and URLs in ... wait for it ... text files! : )
3. My module reads the URL and then creates matching PDFs for each of those URLs.
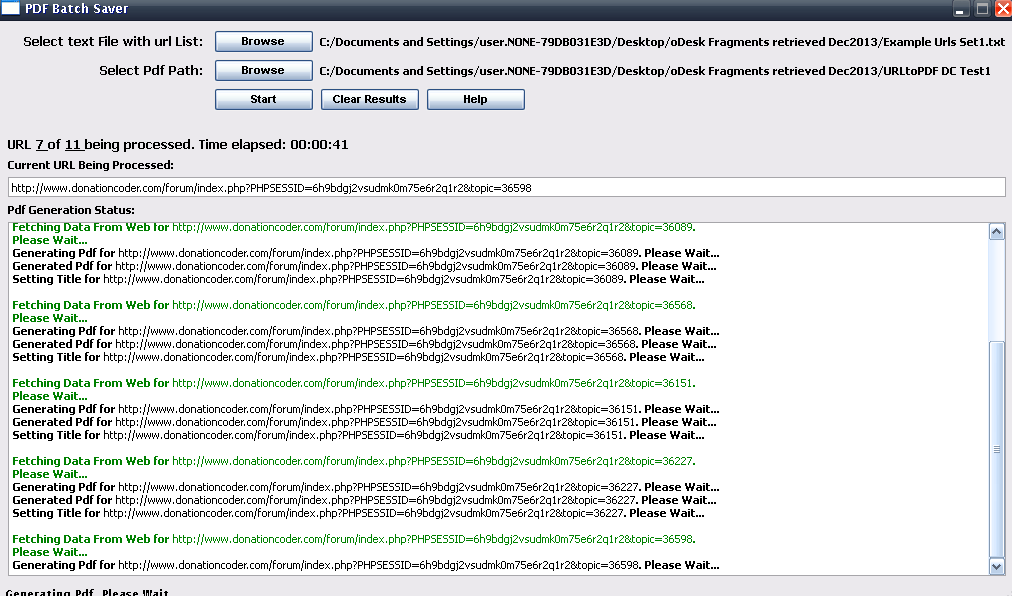
Known bugs:
1. As I just found out in this run, there are some unclear problems with the filenames of the resulting PDFs.
2. We put a bit of thought into how Duplicate URLs in a list are handled. I think the file number in the first character is supposed to keep increasing because it was supposed to be line count equal to the number of original URLs. But this is why this is a component - this part needs work.
3. Misc "Look and Feel" bugs - for example if you're working with a "logged in system" such as email or Monster (my original use case) or other, you might get badly formatted PDFs because the app wouldn't have correct login permissions etc. There are others. That's why I have to sign off with this "only as a component".
4. The package is rather large - it uses QtWebKit I think, and that's more than the post limit here. If anyone wants this piece I'll find somewhere to upload it, maybe my private server.
Some info:
The BBSS thread from Miles is here:
https://www.donation...ex.php?topic=30913.0Attached is the sample title and URL list and a couple of sample output PDFs.

